
 400-626-7377
400-626-7377
Hadoop 2.0:大數(shù)據(jù)的新突破在即
【中培偉業(yè)】以往 Hadoop 似乎就是大數(shù)據(jù)的代名詞。不過最近隨著大數(shù)據(jù)應(yīng)用的深入,大家已經(jīng)越來越傾向于僅僅把它看成是大數(shù)據(jù)的一個存儲工具了。接下來的Hadoop 2.0就為了解決之前所出現(xiàn)的問題。
不過這并不一定就是壞事。把 Hadoop 當(dāng)作廉價有效的存儲正好是 Hadoop 下一階段演進(jìn)的的完美起點(diǎn)。今年夏天就要亮相的 Hadoop 2.0 將會令數(shù)據(jù)倉庫中的信息以及非結(jié)構(gòu)化數(shù)據(jù)池前所未有地容易訪問。
Hadoop大桶
自成為大數(shù)據(jù)工具以來,Hadoop 就是一個非常棒的數(shù)據(jù)存儲系統(tǒng),但是需要開發(fā) Java 應(yīng)用來訪問數(shù)據(jù)的 MapReduce 學(xué)習(xí)起來卻比較困難。
當(dāng)然,還有別的辦法可以從 Hadoop 中獲取信息。Hbase數(shù)據(jù)是 Hadoop 的一部分,它可以讓用戶按照數(shù)據(jù)庫范式來處理數(shù)據(jù)。Hive數(shù)據(jù)倉庫則可以讓你用類 SQL 的 HiveSQL 查詢語言來創(chuàng)建查詢并轉(zhuǎn)化為 MapReduce 任務(wù)。不過 Hadoop 仍受限于單線程性。MapReduce 任務(wù)、Hive 查詢、Hbase 操作,等等,這些都要輪流進(jìn)行。
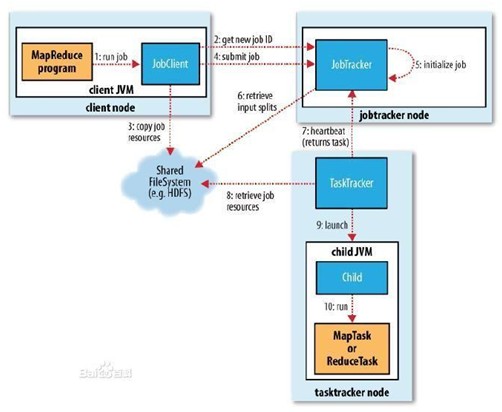
這就是許多大數(shù)據(jù)供應(yīng)商傾向于僅將 Hadoop 當(dāng)作數(shù)據(jù)容器的原因,為了提高效率,他們在此基礎(chǔ)上再開發(fā)自己的工具來獲取或分析其中的數(shù)據(jù)。盡管把 Hadoop 形容為一個大桶很形象,但是Hadoop 用戶當(dāng)中已經(jīng)有人把它看作是數(shù)據(jù)大湖甚至數(shù)據(jù)海洋了。不過光是規(guī)模大還是不行的,那些限制影響到了 Hadoop 的賣點(diǎn)。
Hadoop 的開發(fā)社區(qū)也意識到這個問題,隨著 Hadoop 即將迭代到新的版本,上述限制即將在很大程度上被解除。
YARN解決方案
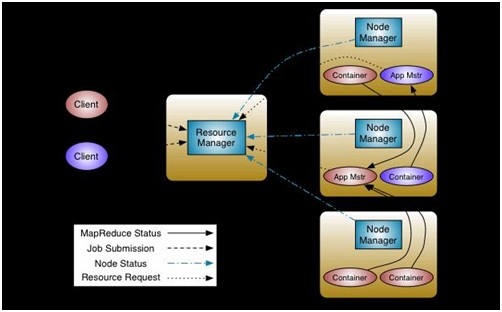
在 Hadoop 2.0 發(fā)布經(jīng)理 Arun Murthy 看來,其最重要的變化是 MapReduce 框架升級為Apache YARN,這將擴(kuò)展 Hadoop 中可以應(yīng)用的軟件種類和應(yīng)用程度。Arun Murthy 本人就是 YARN 項(xiàng)目主管,他指出,Hadoop 1.0 和 2.0 的區(qū)別在于,前者所有的事情都是面向批處理的,而后者則允許多個應(yīng)用同時在內(nèi)部訪問數(shù)據(jù)。
相對于當(dāng)前 MapReduce 系統(tǒng)能處理的事情,把這些功能分開使得 Hadoop 集群資源的管理更加強(qiáng)大。其主要管理方式類似于操作系統(tǒng)對任務(wù)的處理,也就是說不再有一次一項(xiàng)操作的限制了。
有了 YARN,開發(fā)者就能夠直接在 Hadoop 內(nèi)部來開發(fā)應(yīng)用,而不是像許多第三方工具所做的那樣,在外面把數(shù)據(jù)篩選出來。
Murthy 稱,現(xiàn)在已經(jīng)有供應(yīng)商對在 YARN 框架內(nèi)開發(fā)應(yīng)用表現(xiàn)出興趣。Murthy 估計(jì),Hadoop 2.0 的強(qiáng)力 beta 版有可能會在今年 6 月或 7 月推出,正式版則可能在 8 月發(fā)布。
如果 YARN 的確能履行其承諾的話,開發(fā)者將可以在原生的 Hadoop 平臺里方便地接觸到許多的數(shù)據(jù)大湖大海,令搜尋有用信息的任務(wù)更加流暢和便捷。屆時,大數(shù)據(jù)會變得更加有用、更加大眾化。
相關(guān)閱讀





-
全國報名服務(wù)熱線
 400-626-7377
400-626-7377
-
熱門課程咨詢
 在線咨詢
在線咨詢
-
微信公眾號
 微信號:zpitedu
微信號:zpitedu
京ICP備13024721號-1
 京公網(wǎng)安備11010602007294號 增值電信業(yè)務(wù)經(jīng)營許可證:京B2-20201348 全國統(tǒng)一報名專線:400-626-7377
京公網(wǎng)安備11010602007294號 增值電信業(yè)務(wù)經(jīng)營許可證:京B2-20201348 全國統(tǒng)一報名專線:400-626-7377